Data Report
All information on the data used in the project is compiled in the data report in order to ensure the traceability and reproducibility of the results and to enable a systematic expansion of the database. All information about the data used in the project is documented in the data report to ensure the traceability and reproducibility of the results.
1 Raw data
1.1 Overview Raw Datasets
| name | Source | Storage location |
|---|---|---|
| Meteorites | The data are from NASA Open Data NASA is the Federal Agency for Space, Space Research and Aviation Research | Link to Data NASA Downloaded via script from NASA Open Data and not stored in a folder |
1.2 Details Dataset
1.2.1 Description
The Meteorite Landings dataset contains information on known meteorites that have landed on Earth. For each meteorite, details such as the name, geographic location (latitude and longitude), year of landing, mass, and meteorite type are recorded. This dataset allows for analysis of meteorite distribution, frequency, and properties worldwide.
1.2.2 Source
The data is provided by NASA through the NASA Open Data Portal, which collects and publishes scientific data from space research and meteorite observations. NASA is a United States government agency responsible for civilian space exploration and scientific research related to Earth, space, and planetary science.
1.2.3 Data Acquisition
The data used in this project is obtained through a separate data processing script located in the project folder (ds25a-5-fancyproject). This script is executed at the beginning of the workflow and is responsible for downloading and preparing all required datasets.
The raw data is automatically retrieved from the data source when the script is executed and stored in the folder (ds25a-5-fancyproject/data/raw). This ensures that the original dataset is preserved in a reproducible form.
Subsequently, the script performs several data cleaning and preprocessing steps, including type conversions, handling of missing values, and further data preparation tasks. The resulting processed datasets are stored in the folder (ds25a-5-fancyproject/data/processed).
The main application (Shiny app) exclusively uses the preprocessed data from the processed directory and does not directly access any external data sources.
1.2.4 Legal Aspects and Licensing
The dataset is under an open license, allowing free use, sharing, and modification as long as NASA is credited as the source. For commercial use, it is recommended to review NASA’s license terms on their website.
1.2.5 Data Governance
The dataset is classified as public, as it provides scientific information for research and educational purposes and contains no personal data. Within an organization, it can be considered business-relevant for geoscience or environmental data projects.
1.2.6 Data Catalogue
The data catalogue basically represents an extended schema of a relational database.
| Column index | Column name | Datatype | Values (Range, validation rules) | Short description |
|---|---|---|---|---|
| 1 | name | categorical | any string | Name of the meteorite |
| 2 | id | numeric | positive integers 1 to 57458 | Unique identifier of this Dataset not compatible with other datasets |
| 3 | nametype | categorical | “Valid”, “reclict” | Indicates if the meteorite name is valid |
| 4 | recclass | categorical | meteorite classification codes (e.g., L5, H6, EH4) | Classification of the meteorite |
| 5 | mass..g. | numeric | positive numbers 0 to 60000 kg | Mass of the meteorite in grams |
| 6 | fall | cat | “Fell” or “Found” | Whether it was observed falling or later found |
| 7 | year | numeric | 860 to 2026 | Year the meteorite fell or was found |
| 8 | reclat | numeric | -90 to 90 | Latitude of the find location |
| 9 | reclong | numeric | -180 to 180 | Longitude of the find location |
| 10 | GeoLocation | nummeric | format “(lat, long)” | combined latitude/longitude |
1.2.7 Data Chracteristics and Quality
The raw data was analyzed using the ydata_profiling package. It can be found here Raw Data Analysis
2 Processed Data
2.1 Overview Processed Datasets
The conceptual design and creation of this dataset are described in Section Section 1.2.3.
2.2 Details Meteorite_Landings_cleaned.csv
2.2.1 Description
The cleaned dataset has 31,911 meteorite records with complete information on location, mass, year, classification, and fall type. It is our main dataset for all visualizations in this project.
2.2.2 Processing Steps
Rows with at least one missing value in reclat, reclong, mass, year, recclass, or fall were deleted. 7,315 entries had no coordinate data, 291 had no year, and 131 had no mass. One entry with a year value of 2101 was removed as a data entry error, along with 19 entries where mass was zero, which is physicaly impossible. The column mass (g) was renamed to mass_g to avoid issues with special characters, and the year column was converted from float to integer. The cleaning reduce the Entry number from 45,716 to 31,911.
2.2.3 Data Visualisations of the most important variables after cleaning
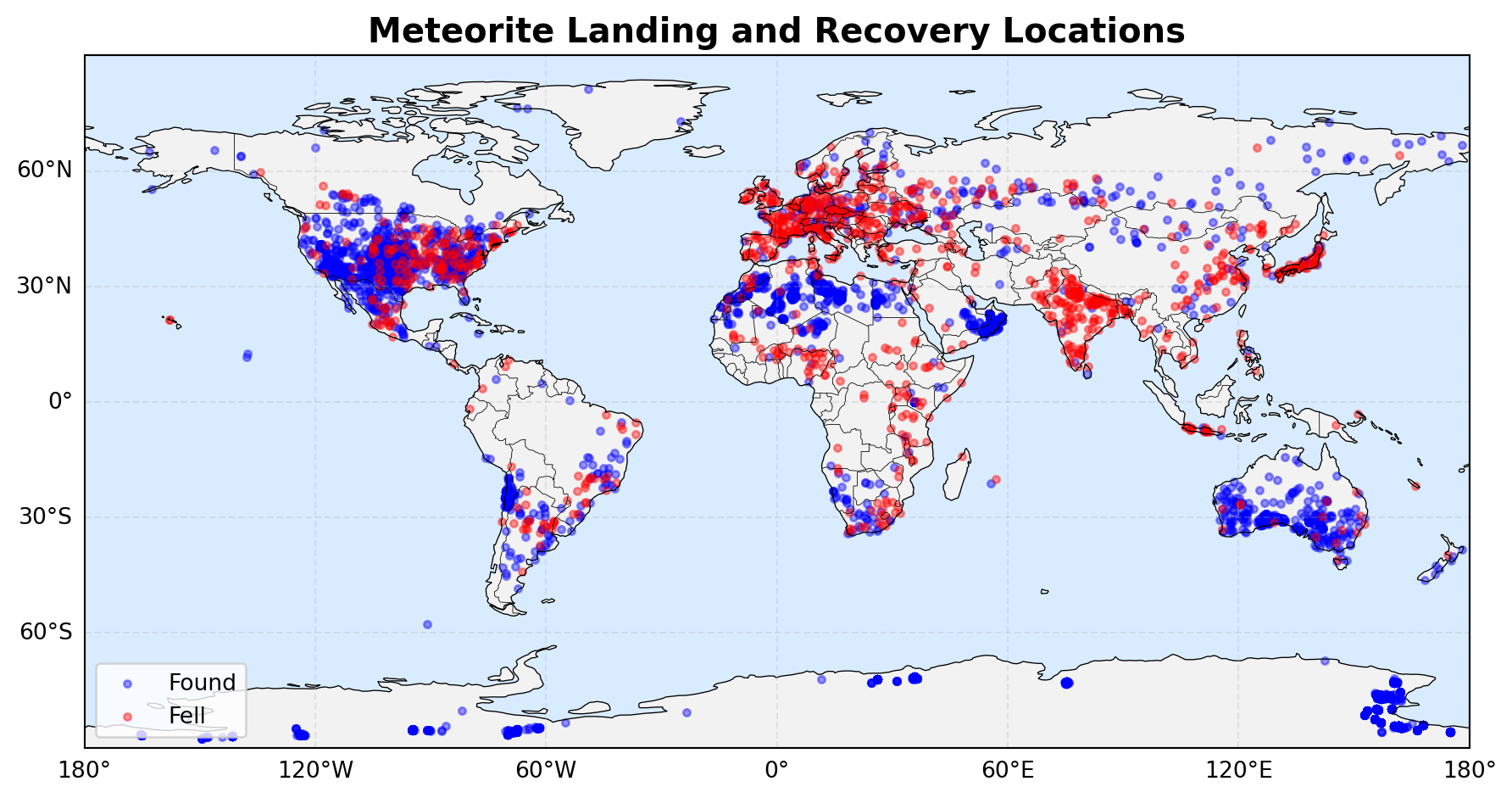
2.2.3.1 Meteoites on the World
The map shows meteorite impact sites around the world, with blue dots representing “found” meteorites and red dots representing “observed falls.” There are particularly many finds in North America, Europe, India, and Australia, as well as in Antarctica, where numerous meteorites are discovered due to the ice sheets.
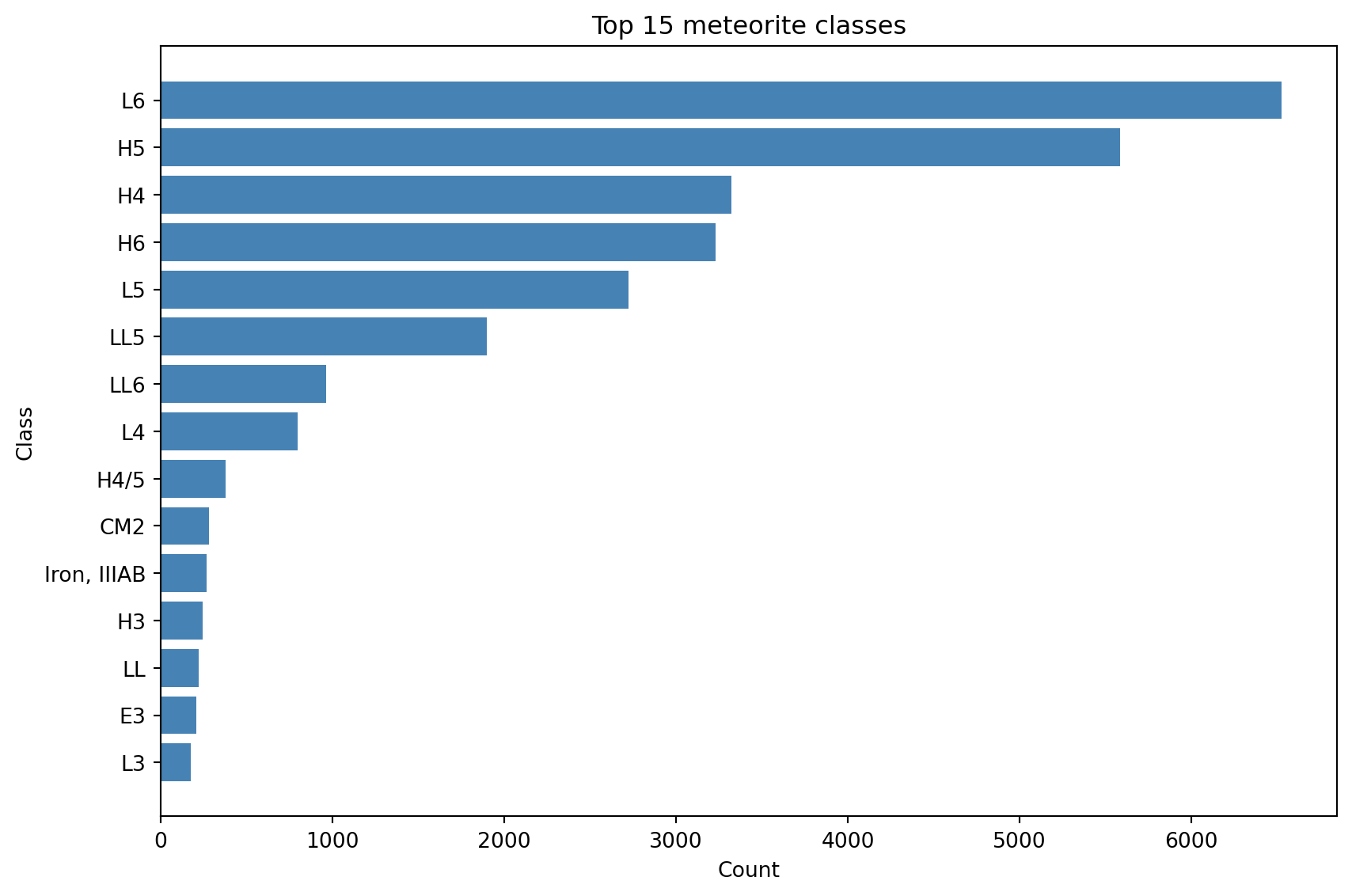
2.2.3.2 Meteorites classes
This shows the top 15 kategories with the most meteorites
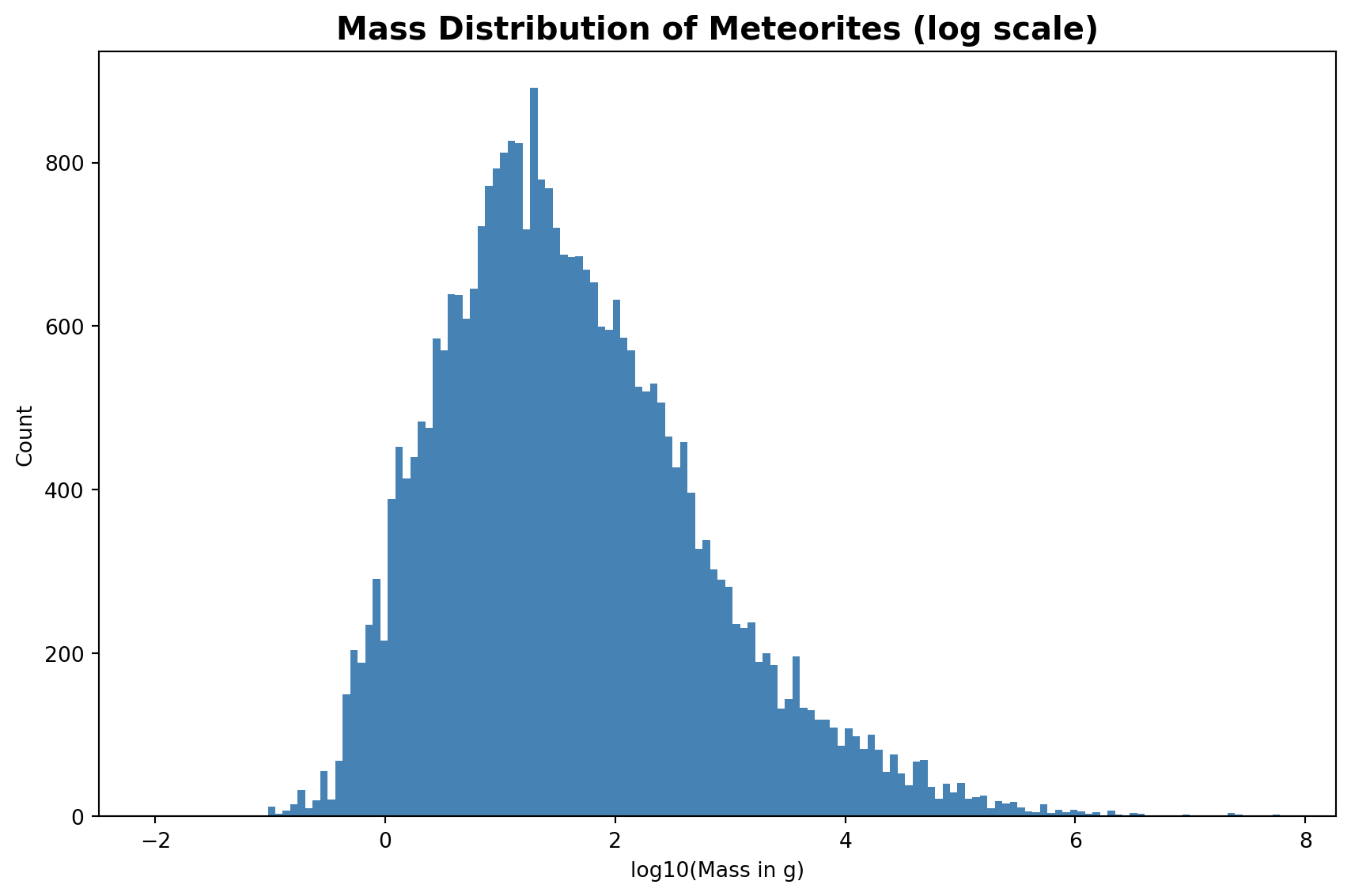
2.2.3.3 Meteorites mass distribution
The histogram shows the mass distribution of all recorded meteorites on a log10 scale. Most meteorites weigh between 1g and 100g (log10 values 0–2). The distribution is roughly bell-shaped on the log scale, which means the underlying data is log-normally distributed. A linear scale is not used because a small number of very heavy meteorites would compress the majority of entries into an unreadable range.
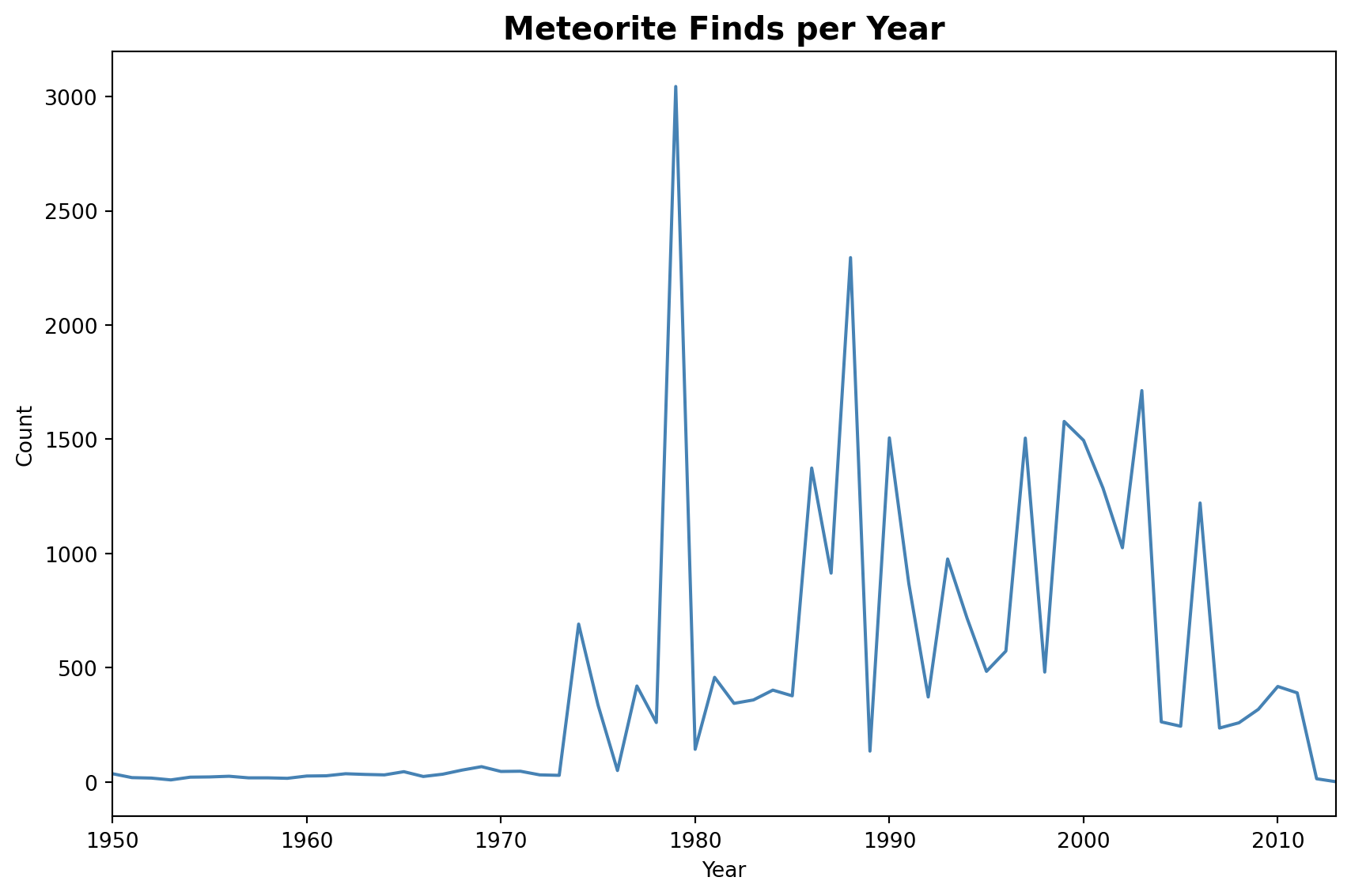
2.2.3.4 Finds over time
The chart shows the number of meteorite finds per year from 860 to 2013. Before 1970, finds were rare and mostly accidental. The sharp increase afterwards reflects the start of systematic search programs in Antarctica and desert regions, where conditions make meteorites easy to spot.